Smarter AI Demands Smarter Context: How Yajur Healthcare is Re-Architecting Clinical Reasoning Pipelines
Not just models. Context. Structure. Trust.
By Manish Sharma | Founder & Director, Yajur Healthcare
1. The Bottleneck Isn’t Intelligence—It’s Clinical Context
At Yajur Healthcare, we’ve repeatedly observed that what holds back AI in real hospital settings isn’t the intelligence of the model—it’s the quality of the clinical environment it’s trying to interpret. A system trained on well-structured academic case reports might demonstrate stellar diagnostic accuracy, but these inputs are a far cry from the messiness of real-world EHRs.
In pilot implementations across global health systems—including projects at institutions like CHOP and a major Belgian hospital—LLMs produced concerning results unless heavily engineered data inputs were provided. In one real case, a model misread a key eligibility rule, misclassifying “no steroid use in the last six weeks” as “recent steroid use stopped five days ago”—an error with clear clinical consequences. These failures aren’t due to flawed reasoning. They arise from the absence of coherent, structured context.
Research:
- Microsoft’s 85% NEJM result is from highly curated teaching cases—similar to giving a med student the best possible test scenario. These are not the fragmented, ambiguous, incomplete records typical of real-world care.
- Real EHRs are a mess: According to multiple studies (e.g., JAMA 2022), the average EHR entry involves over 20 different unstructured or semi-structured elements per encounter—ranging from handwritten discharge summaries to vitals recorded twice by different systems.
- Hallucinations in clinical LLMs are often not bugs, but a feature of working with incomplete inputs. The model is trained to “guess” when data is missing, which is dangerous in medicine.
2. India is rapidly becoming the engine room
As AI becomes more fluent in clinical dialogue, it also becomes more dependent on precisely structured, domain-aware data. Medical language is filled with shorthand, ambiguity, and implied logic. A phrase like “NKDA” or “rule out MI” can lead to entirely different actions depending on context—something even advanced models still struggle to resolve reliably.
This is where human-AI collaboration becomes indispensable. Radiologists and oncologists, for instance, routinely review and refine machine-suggested summaries. Their expertise fills in temporal context, interprets ambiguities, and ensures that AI-generated outputs align with clinical intent—not just statistical language patterns.
At Yajur Healthcare, we’re leveraging India’s skilled, multilingual clinical and data workforce to build datasets and pipelines that are not just annotated, but deeply contextualized by subject matter experts across specialties. This isn’t just labeling data—it’s about building a clinical lens through which AI can safely interpret the patient record.
Research:
- Human-in-the-loop (HITL) is not a fallback; it’s a design principle. In safety-critical domains like healthcare, aviation, and nuclear energy, human oversight is mandatory. According to Stanford HAI and the UK NHS AI Lab, HITL pipelines are essential for validation, exception handling, and bias control.
- The economic flywheel of smarter humans powering smarter AI is beginning to accelerate. McKinsey (2024) notes that 70% of enterprise LLM deployments require some form of domain-specific annotation, summarization, or QA loop—most of it still manual or semi-automated.
- India’s advantage:
- 250,000 freelance and full-time contributors in AI annotation (TeamLease data, 2024)
- STEM pipeline producing 1 million engineering graduates/year
- Deep multilingual base essential for clinical NLP across India’s ~22 major languages
- Medical annotation networks now include physicians, radiologists, coders, and nurses across specialties
Yajur’s Human-in-the-Loop Annotation Pipeline
Building Context, Not Just Labels. At Yajur, we go beyond manual annotation—we’re designing a Human-in-the-Loop pipeline that blends clinical expertise, structured validation, and feedback-aware loops for training and benchmarking AI models.
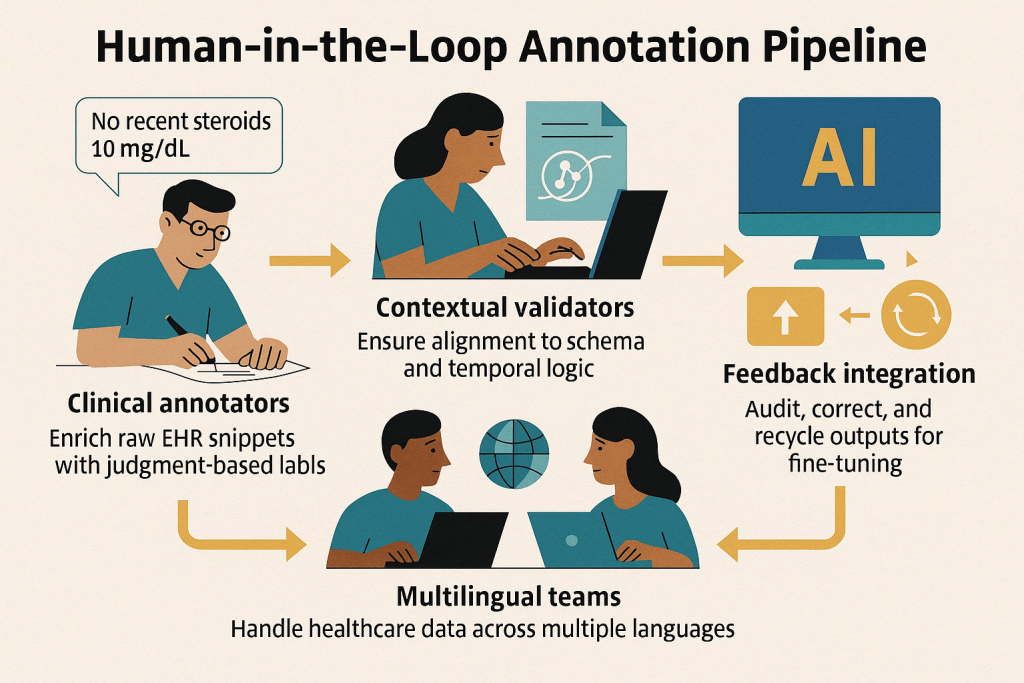
Our goal: To turn messy, unstructured medical records into fine-tuned, high-context training pipelines that fuel the next generation of safe, trustworthy clinical AI agents.
3. LLMs Are Brilliant Interns—But They Can’t Lead Alone
Large language models may operate with high fluency, but they lack situational awareness. They don’t know what they don’t know. While they can generate coherent summaries, they don’t understand the implications of missing lab data or ambiguous phrasing in notes. A model trained on millions of documents may skip over a critical potassium level from a few hours ago—not due to lack of intelligence, but because it lacks the mechanisms for longitudinal memory or uncertainty management.
By contrast, clinicians are trained to identify gaps, spot inconsistencies, and ask clarifying questions. This human intuition is vital, and until AI systems can reliably replicate it, the onus is on infrastructure builders—like Yajur—to create the safety scaffolds models can rely on. This is why Yajur Healthcare isn’t just training models—we’re building clinical reasoning pipelines: systems that detect missingness, flag ambiguity, enforce schema compliance, and escalate when confidence is low. Until models can plan hierarchically and admit uncertainty, we believe safety must come from the pipeline around the model, not the model alone.
4. Compressing history into structured facts
Context engineering is the operating system for safe clinical AI. Throwing massive chunks of unfiltered patient records into a language model doesn’t improve outcomes—it dilutes focus. Transformers, even with large context windows, struggle to retain key clinical signals when irrelevant data floods the input.
That’s why at Yajur Healthcare, we focus on targeted retrieval and structured summarization. Whether it’s extracting the most recent lipid panel or compressing note history into discrete clinical facts, our approach reduces the token load while improving relevance. Outputs are validated against healthcare standards like FHIR and ICD-10, and each recommendation includes a direct citation trail—allowing for real-time auditability.
Every output passes through strict schema validators (FHIR, USCDI, ICD-10), and every recommendation includes a provenance trail—a direct pointer back to the source record or structured field it was derived from.
🔧 Yajur’s Context Engineering Stack
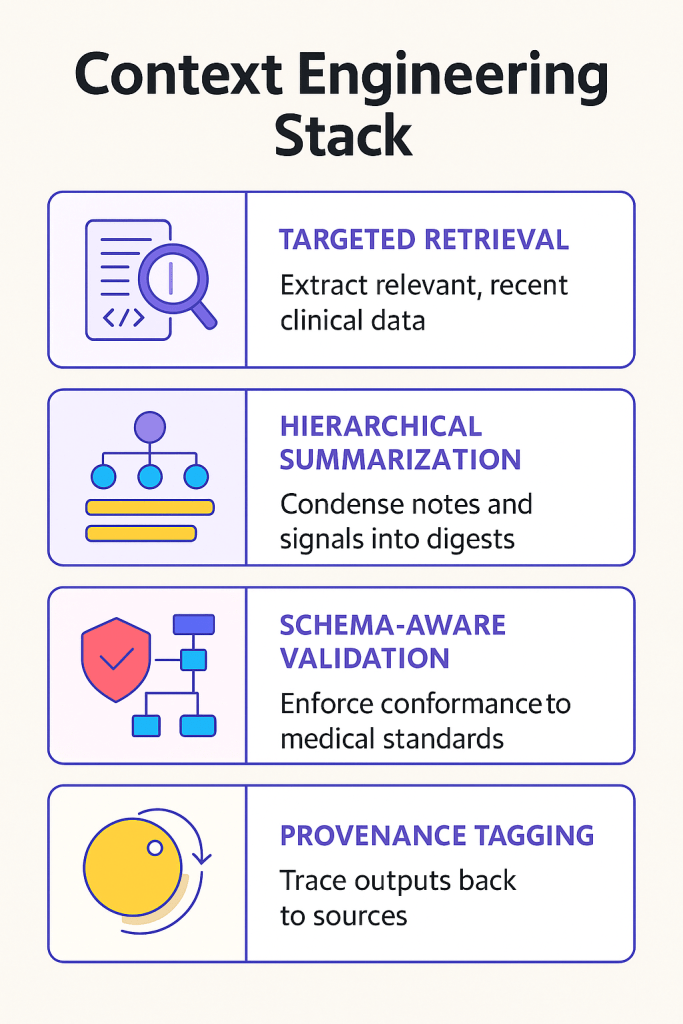
The result? Leaner prompts, faster reasoning, fewer hallucinations—and AI outputs clinicians can actually trust.
5. Models Aren’t Enough. The Infrastructure Around Them Is Everything.
We don’t just need bigger models—we need a smarter ecosystem around them. Building better models is not enough. The true challenge in deploying clinical AI at scale lies in building trustworthy systems around those models—systems that validate, trace, and flag uncertainty.
At Yajur Healthcare, our infrastructure-first approach focuses on delivering AI agents that not only operate safely but also explain their logic, cite their data sources, and defer judgment when ambiguity is high. This is what clinical-grade AI demands—and it’s what we’re designing our entire platform around.
That’s the kind of AI we’re enabling at Yajur Healthcare—and we’re looking to collaborate with those building agentic systems, context-aware pipelines, and trustworthy clinical LLMs.
🔗 Let’s connect if you’re working on:
- Retrieval-augmented agents
- LLM orchestration in EHRs
- Multilingual medical NLP
- Human-in-the-loop data validation at scale
This article was originally published on the HCITExperts Blog by Yajur Healthcare.